Are you irritated at the fact that LogMeIn gave virtually no notice as to doing away with their free service? Consumers as much as small businesses were impacted if they did not subscribe to LogMeIn Central or Pro. Here are some alternatives that may be of value and definitely worth looking into.
As always, please don't hesitate to contact TPUServices with questions! We're here to help!
~The TPUServices™, LLC Team
5 alternatives to LogMeIn Free for remote PC access
- Jan 28, 2014 3:00 AM
LogMeIn Free is
gone, but don’t panic: You can find alternative remote-access tools
that cost the same low price of nothing at all. Whether you need to
access a document, collaborate with a colleague, or support several PCs,
try one of these free tools to get back into the game.
TeamViewer
I’ve been using TeamViewer for
years to help out family and friends, and it has always been reliable.
Simply download the program from the company’s website, and then install
it (or run it without installation, if you desire) on both of the PCs
you want to connect. During installation, you can also set the program
for unattended control.
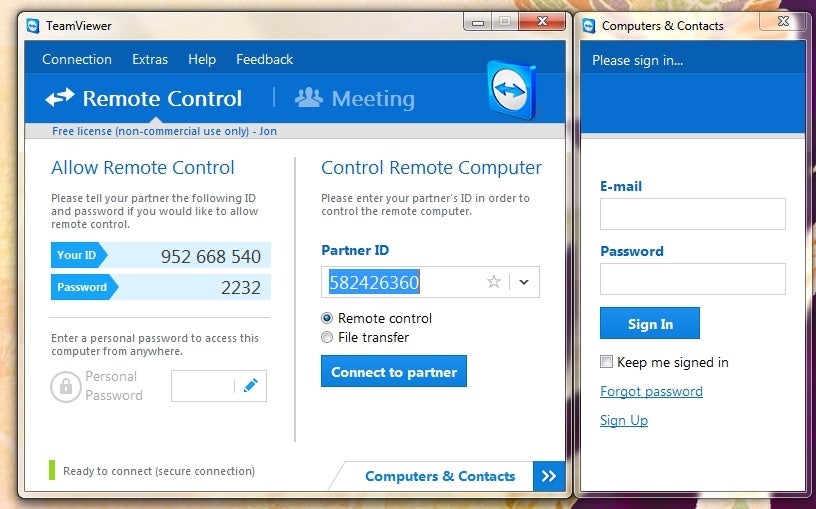
TeamViewer gives you easy, secure remote access to multiple computers.
For
ad hoc use, simply run the program and log in from the controlling
computer. The two components will connect, and up will pop a window
containing the desktop of the computer to be controlled. TeamViewer
installs as both a server and a client, so you can use it to take
control or to allow control.
TeamViewer
9’s cooler features include the ability to open multiple remote
sessions in tabs (as in a browser), cut and paste between computers via
the clipboard, and drag and drop files from your desktop to the remote
desktop. It’s a mature, stable, practical tool for anyone’s
remote-control needs. Note that you’ll get the occasional message about
upgrading to the pay version if you use TeamViewer regularly to connect
to a lot of different PCs. You’re on your honor for that one.
Windows Remote Desktop
Although Windows
Remote Desktop doesn’t support true screen-sharing (the screen of the
controlled computer goes black instead of staying live) the way services
such as Join.me and TeamViewer do, this built-in tool is free and fast,
and it allows complete remote control over PCs. There’s even Microsoft
Remote Desktop for the Mac, so you can remotely access your more
artistic acquaintances’ Apple products.
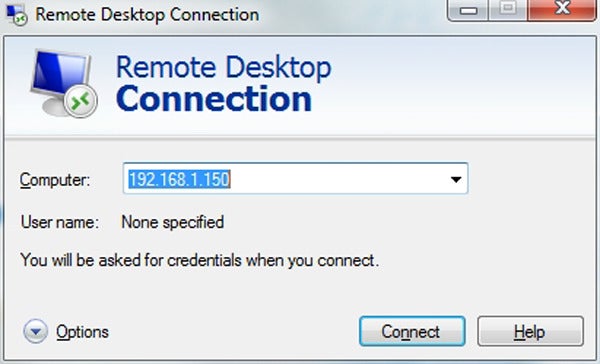
Don’t underestimate the power of Windows’ built-in remote-connectivity tool.
The
basic concept behind Windows Remote Desktop is to let users control
their office computer remotely so that they can work from home. Hence,
although all versions of Windows (Basic, Home, and so on) can establish a
Remote Desktop connection and control a PC, only the Professional,
Business, and Ultimate versions of Windows can be controlled.
As most office
computers are one among many on a network, you need to have the office
router tweaked to forward a port (3389) to the PC you want to control.
You can edit the Registry to allow control of more than one PC by adding
more ports, but that’s a very techie task.
Windows Remote
Desktop works great once you’ve set it up, but if you want to control
multiple PCs on a regular basis, the next option might be better for
you.
VNC
VNC,
or Virtual Network Computing, isn’t itself a product, but an
open-source remote-control and display technology that’s implemented by Tight VNC
(free), Ultra VNC (free) and RealVNC (free and pay), among other
parties. VNC isn’t hard to use, but it’s not as simple as Join.me and
TeamViewer, which don’t require user knowledge of IP addresses.
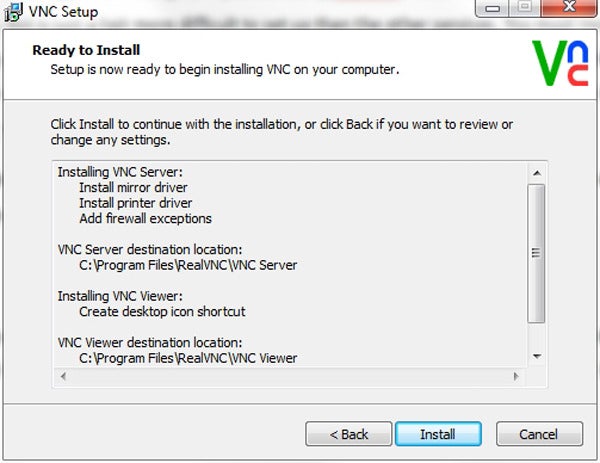
VNC is a good option if you need to control multiple PCs regularly.
To
use VNC, install it on both the PCs you want to connect and then set
them to listening. To control another PC, simply open the VNC viewer
(client), enter the PC’s IP address, and have at it. You may also have
to open port 5900 on your firewall and router, and to direct said port
to the PC you want to control.
You can use VNC to
connect to multiple PCs behind a public IP by opening and using more
ports. Most VNC implementations install both the server and viewer
software by default, so (as with TeamViewer) you can control in either
direction.
Though it’s a tad difficult to set up, VNC is cross-platform (Windows, Mac, Linux), and it works extremely well once installed.
Join.me
Join.me is
a meeting service (free and pay) from LogMeIn that also provides remote
control. It’s convenient for impromptu support in that all you need on
the controlling PC is a Web browser. The user with the computer that
will host the meeting (and offer control) simply surfs to the Join.me
site, selects Start Meeting, and downloads a file.
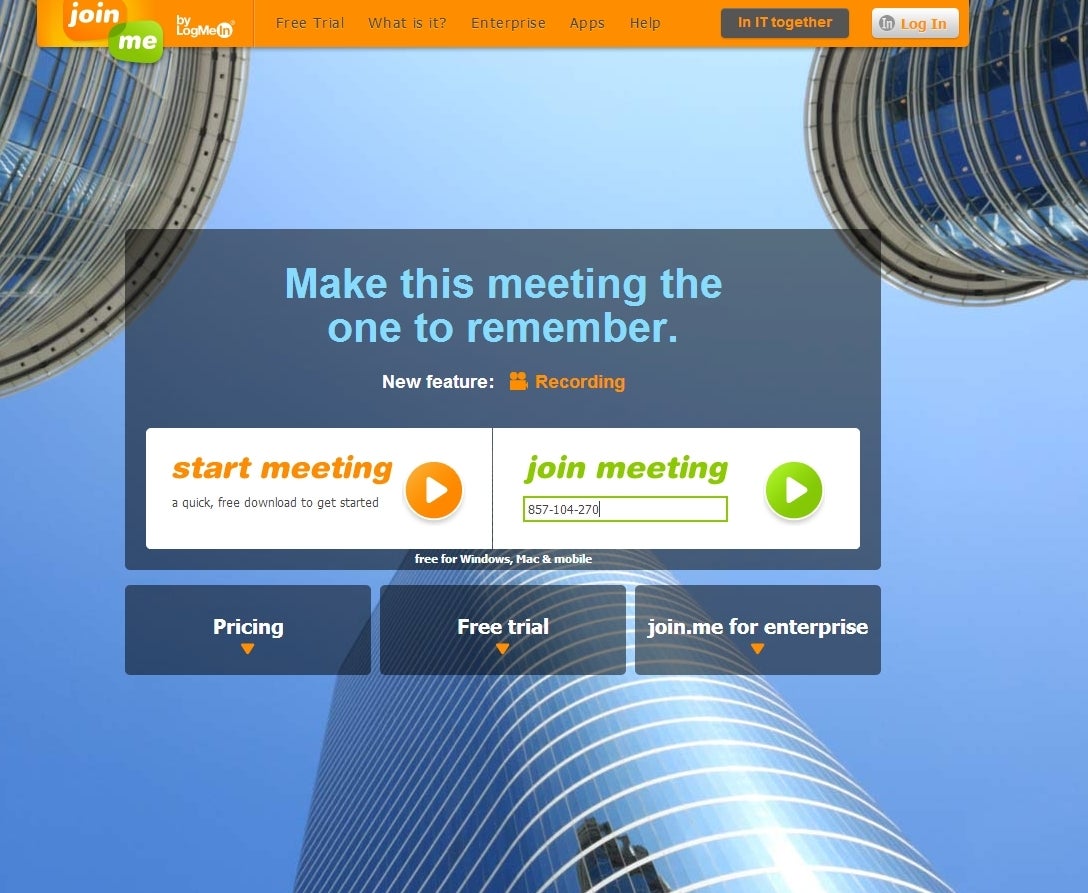
Meeting service Join.me also offers remote access—all you need is a Web browser.
After
running said file, the meeting originator passes the provided
nine-digit passcode to the user or users on the other end, who in turn
enter the passcode in the Join Meeting field on the Join.me homepage.
The meeting originator’s desktop will appear in the browser. Once remote
control is granted, you can chat, send files, and more. Easy-peasy, but
note that Join.me isn’t suited for unattended remote control, which
makes it only a partial replacement for LogMeIn.
WebEx Free
Most users think of WebEx as
a tool for multiuser boardroom meetings, but it’s also perfectly
suitable for small-scale, live (not unattended) remote control and
support. WebEx works a little differently from Join.me in that
installing software is required at both ends, but that’s a relatively
painless procedure.
WebEx: Not just for multiuser meetings.
Once
users have joined the meeting, initially they can only view the
originator’s desktop, but the originator can make another person the
presenter, pass control over the mouse and keyboard, and share files,
chat, and utilize webcams for face-to-face interaction. There’s a bit of
a learning curve if you stray from the main features (available from
the usual drop-down panel at the top of the display), but overall WebEx
is quite easy to use.
Don’t get spoofed
Because of the popularity of remote-control and remote-meeting services,
the Web is rife with spoof sites (those that look very much like the
correct one, but aren’t) that will attempt to lure you in if you don’t
type the URL correctly. Downloading software from these sites can be
dangerous to your computer’s health, as well as to your wallet.
Sometimes the bad guys will try to sell you support.
The correct site addresses for the services I’ve mentioned are:
- TeamViewer — http://www.teamviewer.com/en/index.aspx
- RealVNC — http://www.realvnc.com/
- Join.me — https://join.me/
- WebEx Free — http://www.webex.com/
Thanks to the growth in distributed and mobile workforces, the ability
to access and control a PC remotely is a must for workers and IT
administrators alike. That’s why we’ll all miss LogMeIn Free. But if you
really love one of these free alternatives, consider throwing a few
bucks to the developer. Who knows: Your contribution could help to keep
the program going for everyone.



